In Fall 2017, the Data Science Discovery Program gave 50 Berkeley undergraduates the chance to deepen their learning in more than a dozen data science projects across a fabulously wide set of domains. Data science skills let students discover new knowledge and create solutions across a broad range of areas. The Data Science Discovery Program allows them to explore their interests and build their own pathways from Berkeley’s data science classes directly into hands-on research. The program opens doors for students coming out of the pathbreaking Data 8 freshman course (Foundations of Data Science) as well as more advanced classes. Participants find themselves integrated into an ongoing multidisciplinary learning community with Berkeley’s graduate students, postdoctoral scholars, and data-driven staff.

Highlights from Fall 2017
From the Energy Resource Group’s SWITCH Mexico energy modeling project (Grand Prize Winner at the UN Data Challenge for Climate) to mapping social networks of ancient Sumeria with data extracted from cuneiform tablets, Data Science Discovery students got a chance to experience the richness and power of their data science skills. They contributed to understanding the effects of climate change and hurricanes on Puerto Rico’s rainforest ecology, tracing patterns in bankruptcy proceedings, and advancing the university’s own data infrastructure.
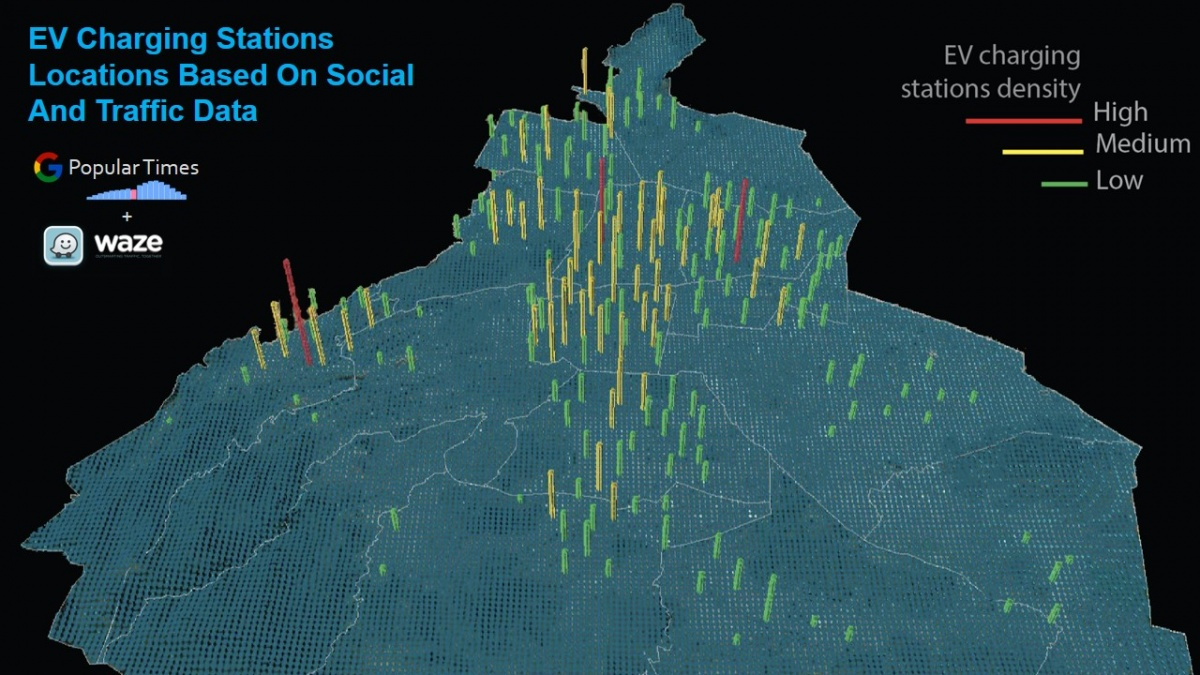
SWITCH Energy Systems Modeling - Mexico
Project Leader: Sergio Castellanos (Energy and Resources Group)
Students helped build a visualization of the air quality impact of different energy policies based on energy consumption in Mexico City in order to reduce air pollution and greenhouse gas emissions. The team used data from Waze that showed how people used their cell phones to optimize their routes, which built a picture of where congestion and pollution is occurring in Mexico City. They then carried out modelling analysis to understand how electric cars would affect pollution and greenhouse gas emissions. Students worked around the clock to complete the project and were honored with the Grand Prize at the UN Data Challenge for Climate Action.

Berkeley Tropical Rainforest Ecology Data
Project Leader: Christine O’Connell (Environmental Science, Policy, and Management)
One of the major uncertainties in predicting future climate is how terrestrial ecosystems will be altered by climate shifts. To improve predictions of how drought, hurricanes and changing climate may impact an ecosystem’s soil moisture and oxygen patterns in the future, students used the statistical programming language R to create a dataset that has high resolution across space and time using temporal patterns in publicly available field and climate data sets.

Detecting Signals of Distant Life in the Universe
Project Leader: Steve Croft, Gerry Zhang, and Andrew Siemion (Berkeley SETI Research Center)
Simple classical statistical techniques are insufficient to find complex transmissions that might come from alien civilizations in a sea of cosmic background noise and human radio interference. A large team of students learned TensorFlow and deep learning models to tackle petabytes of radio data coming from space. They developed code to extract features from image-like radio data, visualize and explore patterns using PCA and clustering, and applied unsupervised and supervised approaches to find signals of interest.

Imaging to Detect Disease
Project Leaders: Maryam Panahiazar & Dmytro Lituiev (UCSF)
Students worked with the Hadley Laboratory at UCSF to begin developing ways to improve patient outcomes and reduce mortality by applying computer vision to improve detection of breast cancer and kidney diseases. They also explored estimating clinical costs by using deep learning regression models on chest X-rays.
Predicting Firesales in Bankruptcy
Project Leader: Elias Name and Christopher Hench (Social Sciences D-Lab)
As part of the first large-scale study that relies on the text of bankruptcy court documents, students used new methods of analyzing text to understand how bankruptcy court proceedings actually work: for instance, how often motions to expedite and ignore deadlines from the Bankruptcy Rules are made and under what conditions they are granted. Unlocking these and similar untapped resources for research could revolutionize legal studies.
Sumerian Text Project
Project Leader: Adam Anderson (Near Eastern Studies)
Sumerian is the oldest written language in the world, written in cuneiform. Tens of thousands of cuneiform documents have been digitized in transliteration (in Roman alphabet) in an online database dealing with taxes, agriculture, trade, and other matters. Students assigned roles and professions to personal names, clustered them, and then graphed a comprehensive social network. Work will continue in the future by finding strong correlations between particular nodes and improving the basis on which the relationship between nodes is built.
Berkeley Business Intelligence Tool
Research Leader: Aswan Movva (Cal Answers Team)
Cal Answers is UC Berkeley’s central information repository, integrating information from many different campus systems. The campus would benefit from a business intelligence tool by means of which ad-hoc queries can be built in an easier and simple way, so staff can get ready answers to critical questions. Significant progress was made in building an interactive ad-hoc BI Reporting solution so users can get high-level data with a simple search query against the data source. The team hopes to scale up development next semester.
Jupyterhub Ecosystem Analysis
Project Leader: Anthony Suen (Division of Data Sciences)
JupyterHub allows hundreds to thousands of users to easily interact with a data science notebook within their browsers without needing a local installation. The team made case studies of JupyterHub deployments worldwide and scraped data to create institutional growth charts for data science ecosystems across the world. The team will continue to collaborate with Project Jupyter, the Binder team, XSEDE (the Extreme Science and Engineering Discovery Environment), and Compute Canada to work on an overall plan for a federated JuptyerHub network, and with the Moore Foundation to build up a database of the growth of data science.
Jupyterhub Discovery Engine
Project Leaders: Joshua Quan (The University Library) and Anthony Suen
Dataverse allows the University Library to improve preservation, discoverability, and exploration of university research and datasets. Students collaborated with the University Library and Jupyter team to create a Dataverse and integrate it with the Binder platform. They plan refine that system along with a Dataverse search function in Jupyterlab in Spring 2018.

About the Data Science Discovery Program
The Data Science Discovery Program is a fast-growing part of Berkeley’s Undergraduate Discovery Experience initiative. It lets students build on foundational knowledge they gain in Berkeley’s rapidly expanding undergraduate Data Science courses. At the same time, it lets researchers across campus tap into the large, diverse pool of undergraduate data science talent.
Students apply through a common portal where they describe their skills and interests. A project team based in the Berkeley Institute for Data Science and the Division of Data Sciences matches them with one of the diverse array of incubated data science projects. After a student is interviewed and onboarded on a project, the team continues to provide support including computational resources and project management assistance. The Data Science Discovery Program has been growing at Berkeley since 2015, when it was piloted as the BIDS Collaborative. From a freshman who has just completed Data 8 or a junior taking a machine learning course, the BIDS Discovery Program allows students to build a pathway from their data sciences courses to a multi-semester data science research experience.
Plans for Spring 2018
New efforts in Spring 2018 will enhance the experience of students and researchers. These include:
-
Piloting a Data Science Management Fellows Program with graduate students from Haas to help manage data science projects with Skydeck.
-
Integrating the Discovery Program with Data Scholars, which will give students from underrepresented opportunities to work in a data science project.
-
Utilizing the Data Peers Consulting services for undergraduates in Moffitt Library.
-
Extending research project solicitation and recruitment periods.
-
Creating a full Application Tracking System to replace current application surveys
-
Improving outreach with weekly blogs about research progress of students teams.